AI 기반 Kubernetes 모니터링 플랫폼

Kubernetes 클러스터 이상 탐지 및 RAG 기반 LLM 분석 플랫폼. Kubernetes 환경에서 발생하는 복잡한 매트릭, 로그, 클러스터 이벤트를 실시간으로 통합 수집 및 분석하며, RAG구조를 기반으로 한 LLM 분석 계층을 결합하여 장애의 근본 원인을 추론하고 대화형 진단 결과를 제공합니다.
담당 역할
AI 파트 담당. FastAPI 서버 설계 및 구현, 이상 탐지 파이프라인 구축, RAG 및 LLM 연동.
// 아키텍처
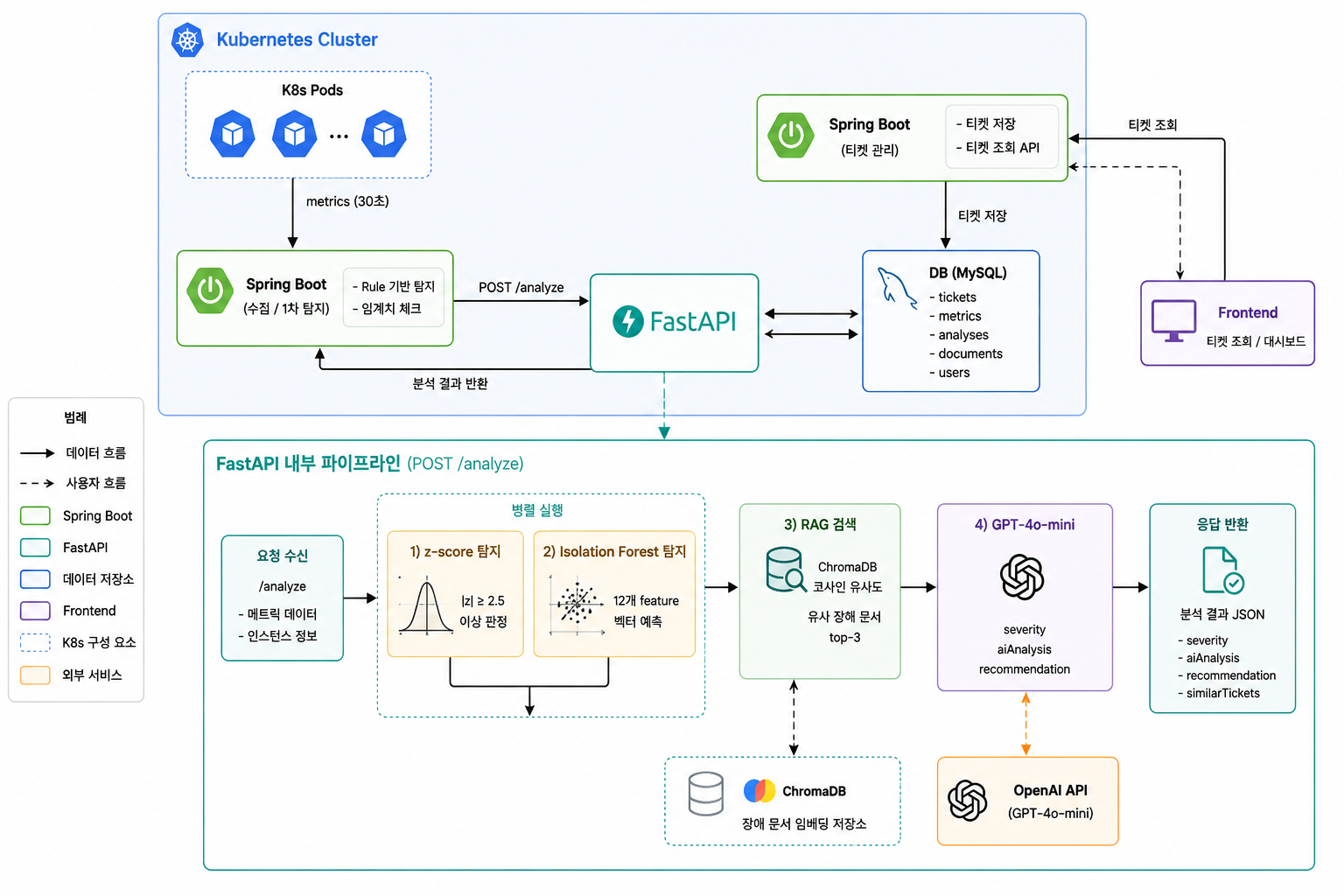
설계 근거
Spring Boot 메트릭 수집 → FastAPI AI 분석 → 4단계 파이프라인(z-score → ML → RAG → LLM)으로 점진적 정밀도 향상
// 기술 스택
선택 이유: asyncio.gather로 z-score·ML 탐지를 병렬 실행하는 비동기 파이프라인 구현에 적합
선택 이유: 정상 데이터만으로 학습 가능한 비지도 학습 — 레이블 없이 이상 탐지 가능
선택 이유: HNSW 코사인 유사도 기반 경량 로컬 벡터 DB로 RAG 유사 사례 검색
선택 이유: JSON 모드 강제·temperature 0.2로 일관된 분석 결과 확보, rule-based fallback 내장
선택 이유: GitHub Actions로 ECR push 후 kind 클러스터까지 자동 배포
// 문제 해결 경험
ML 모델 초기 학습 데이터 부족
초기 배포 직후 정상 Pod 데이터가 없어 Isolation Forest가 미학습 상태로 ML 탐지가 전혀 작동하지 않음
training_store 설계 — 정상 Pod 데이터를 200개 이상 누적하면 자동 학습하고, MLDetector.reload()로 서버 재시작 없이 새 모델을 핫리로드. 미학습 상태에서는 ML 탐지를 스킵하고 z-score + LLM으로만 분석을 이어감
운영 중 데이터가 축적되면 ML 탐지가 자동 활성화되고, /health 엔드포인트의 ml_sample_count·ml_is_trained 필드로 학습 상태를 실시간 확인 가능
// 회고
z-score·ML·RAG·LLM 4단계 파이프라인을 직접 설계하고 asyncio.gather로 독립적인 탐지 단계를 병렬 처리해 지연을 줄임. 각 단계 결과가 다음 단계의 컨텍스트로 누적되는 구조를 직접 구현한 경험
LLM 응답까지 포함하면 분석 한 건에 수 초가 소요되어 실시간성에 한계. Spring Boot의 read timeout(10초) 안에 맞춰야 해 타이트한 구조
LLM 응답을 SSE 스트리밍으로 전달해 체감 지연을 낮추거나, 정상 데이터가 충분히 쌓인 뒤 ML 단독으로 빠르게 판정하는 경량 모드 추가